Storage of digital data has reached unprecedented levels with the ever increasing demand for information in electronic format by individuals and organizations, ranging from the disposal of traditional storage media for music, photos and movies, to the rise of massive applications such as social networking platforms.
Until now, relational database management systems (DBMS) have been the key technology to store and process structured data. However, these systems based on highly centralized and rigid architectures are facing a conundrum: The volume of data currently quadruples every eighteen months while the available performance per processor only doubles in the same time period. This is the breeding ground for a new generation of elastic data management solutions, that can scale both in the sheer volume of data that can be held but also in how required resources can be provisioned dynamically and incrementally.
Although managing large amounts of data efficiently in a distributed fashion has been addressed in the context of Grid computing and peer-to-peer systems, the inherently cooperative, or sometimes downright hostile, nature of these infrastructures and the limited scope of data access patterns, restricts their applicability as an elastic alternative to the relational DBMS in a business environment. The conventional approach of simple server collocation, physical or virtual, although cheap and flexible, also fails to meet the requirements as the onus of scalability and fault-tolerance rests on the final application.
A renewed approach to the problem emerges through the combination of a new business model with highly decentralized, scalable, and dependable systems capable of storing and processing large volumes of data under the Cloud Computing moniker: The infrastructures initially built to meet internal requirements are currently being commercialized as collections of high level services that together realize the vision for elastic data storage and processing. Fundamental to this trend is the recognition of the system as commercially exploitable and the importance of keeping control of the whole infrastructure under the same administrative, or at least, ownership domain. These have a profound impact on both the system assumptions and expectations leading to new opportunities and challenges.
Regarding structured data management, the first generation Cloud Computing services is exemplified by Google's Bigtable, Amazon's Dynamo, FaceBook's Cassandra and Yahoo's PNUTS. Having all started from similar requirements, aiming at supporting their respective global Web operations, they ended up providing a similar service: A simple tuple store interface, that allows applications to insert, query, and remove individual elements, forfeiting complex relational and processing facilities, and most strikingly, transactional guarantees common in traditional DBMS. By doing so, these services focus on a specific narrow trade-off between consistency, availability, performance, scale, and cost, that fits tightly their motivating very large application scenarios.
The current trade-off is much less attractive to common business needs, in which there isn't a large in-house research development team for application customization and maintenance. It is also hard to provide a smooth migration path for existing applications, even when using modern Web-based multi-tier architectures. This is a hurdle to adoption of Cloud Computing by a wider potential market and thus a limitation to the long term profitability of businesses model.
The Stratus project aims at advancing the state of the art by skewing the current trade-off towards the needs of common business users, thus providing additional consistency guarantees and higher level data processing primitives that ease the migration from current DBMS. This requires determining adequate compromises and abstractions, and then devising mechanisms to realize them. The achievement of these goals is to be demonstrated by a proof-of-concept providing a conflict-free, strongly consistent data storage, with in-place processing capabilities, while allowing to leverage large computing infrastructures with distributed storage capabilities.
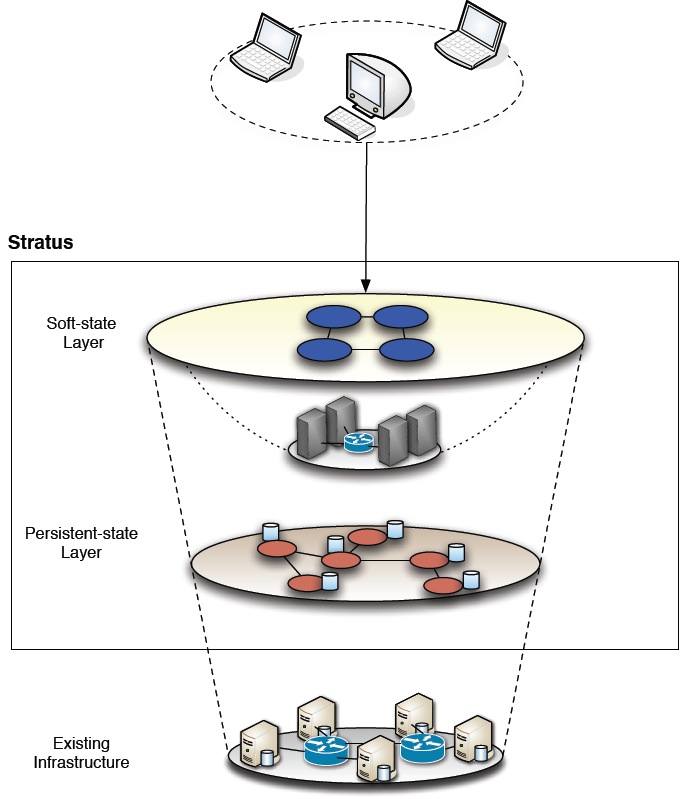
Our main drive in this project is the exploitation of several techniques of optimistic data management strategies, such as optimistic concurrency control, replica management and speculative execution, to reduce the impact of stronger consistency criteria in the performance and scalability of the system.
Our approach to the problem is modular and rests on the use of an architecture with two collaborating layers of distinct structural and functional characteristics. Each layer tackles different aspects of the system, thus making specific assumptions over the computation model and exploiting different techniques to data management and propagation. With these two layers architecture we are able to clearly separate and address the concerns of, on one hand ensuring a strong consistent data storage and, on the other to leverage a massive and highly dynamic infrastructure.